Go to the first, previous, next, last section, table of contents.
Ce chapitre décrit l'utilisation de base de FFTW, i.e., comment calculer la transformée de Fourier d'un simple tableau. Ce chapitre donne la vérité mais pas toute la vérité. Spécifiquement, FFTW implémente des routines et des drapeaux additionnels, fournissant des fonctionnalités additionnelles, qui ne sont pas documentées ici. Il faut voir la Section Référence FFTW, pour une information plus complète. (Notez que vous devez compiler et installer FFTW avant de pouvoir l'utiliser dans un programme. Voyez la Section Installation et Personnalisation, pour les détails de l'installation.)
Ici, nous supposons une installation par défaut de FFTW.
Dans certaines installations (particuliairement à partir des
paquet binaires), les fichiers d'en-tête et les bibliothèques
FFTW sont préfixées avec `s'
ou `d' pour indiquer les versions en simple
ou double précision, respectivement. L'usage de FFTW est, dans
ce cas, le même, excepté pour les directives #include
et les commandes de liaison qui doivent utiliser le préfixe
approprié. Voir la Section Installer
FFTW dans les précisions simple et double, pour plus
d'informations.
Ce chapitre de formation est structuré comme suit. La Section Formation sur la Transformée Complexe à Une dimension décrit l'usage de base de la transformée à une dimension de données complexes. La Section Formation sur la Transformée Complexe Multi-dimension décrit l'usage de base de la transformée à multi dimension de données complexes. La Section Formation sur la Transformée Réelle à Une dimension décrit la transformée à une dimension de données réelles et son inverse. Finallement, la Section Formation sur la Transformée Réelle Multi dimension décrit la transformée multi dimension de données réelles et son inverse. Nous vous recommandons de lire ces sections dans l'ordre où elles sont présentées. Nous allons ensuite discuter de deux sujets en détail. Dans la Section Format de Tableaux Multi dimension, nous discutons des alternatives variées pour stocker les tableaux multi dimensionnels dans la mémoire. La Section Mots de Sagesse montre comment vous pouvez sauvegarder les plans FFTW pour une utilisation ultérieure.
L'utilisation de base de FFTW est simple. Un appel typique pour FFTW ressemble à :
#include <fftw.h>
...
{
fftw_complex in[N], out[N];
fftw_plan p;
...
p = fftw_create_plan(N, FFTW_FORWARD, FFTW_ESTIMATE);
...
fftw_one(p, in, out);
...
fftw_destroy_plan(p);
}La première chose à faire est de créer un plan : un objet qui contient toutes les données dont FFTW a besoin pour traiter la FFT, en utilisant les fonctions suivantes :
fftw_plan fftw_create_plan(int n, fftw_direction dir, int flags);
Le premier argument, n, est la taille de la transformée
que vous voulez calculer. La taille n peut être tout entier
positif mais les tailles qui sont le produit de petits facteurs, sont
transformées plus efficacement. Le second argument, dir,
peut être soit FFTW_FORWARD soit FFTW_BACKWARD,
et indique la direction qui vous intéresse dans la
transformée. D'une manière alternative, vous pouvez
utiliser le signe de l'exposant dans la transformée, -1 ou +1,
qui correspond à FFTW_FORWARD ou FFTW_BACKWARD
respectivement. L'argument flags est soit FFTW_MEASURE
ou FFTW_ESTIMATE. FFTW_MEASURE signifie que
FFTW tourne actuellement et mesure le temps d'éxécution
de plusieurs FFTs pour trouver le meilleur moyen de calculer la
transformée de taille n. Cela peu prendre du
temps, en fonction de votre installation et sur la précision
du timer de votre machine. FFTW_ESTIMATE, par contre, ne
fait aucun calcul et réalise simplement un plan qui peut être
sous-optimal. En d'autres mots, si votre programme effectue plusieurs
transformations de la même taille et que le temps
d'initialisation n'est pas important, utilisez FFTW_MEASURE;
sinon, utilisez l'estimation. (Un compromis entre ces deux extrèmes
existe. Voir la section Mots de
Sagesse.)
Une fois que le plan a été crée, vous pouvez
l'utiliser autant de fois que vous voulez pour les transformées
sur les tableaux de la même taille. Lorsque vous en avez
terminé avec le plan, vous le désallouez en appelant
fftw_destroy_plan(plan).
La transformée elle-même est calculée en
passant le plan dans les tableaux d'entrée et de sortie de
fftw_one:
void fftw_one(fftw_plan plan, fftw_complex *in, fftw_complex *out);
Notez que la transformée
est externe : in et out doivent pointer sur
des tableaux distincts. Elle opère sur les données de
type fftw_complex, une structure de donnée avec
des composants en virgule flottante réelle (in[i].re)
et imaginaire (in[i].im). Les tableaux in
et out doivent avoir la taille spécifiée
lors de la création du plan. Une fonction alternative, fftw,
vous permet d'effectuer efficacement des transformées
multiples et/ou des transformées à tableaux discontinus
(voir Section Référence
FFTW).
Les résultats de la DFT sont stockés dans l'ordre
dans le tableau out, avec la valeur continue (DC) dans
out[0]. Le tableau in n'est pas modifié.
Les utilisateurs peuvent noter que FFTW calcule une DFT non
normalisée, le signe des exposants étant donné
par le paramètre dir de fftw_create_plan.
Donc, calculer une transformée directe puis une inverse (ou
vice versa) donne le tableau original avec une taille de n. Voir la
Section Ce que FFTW Calcule
Réellement, pour la définition de la DFT.
Un programme utilisant FFTW doit être linké avec
-lfftw -lm sur les systèmes Unix ou avec les
bibliothèques FFTW et mathématiques standard en
général.
FFTW
peut aussi calculer la transformée quelque soit le nombre de
dimensions (rang). La syntaxe est identique à celle de
la transformée à une dimension avec `fftw_'
remplacé par `fftwnd_' (qui signifie "fftw
à N dimensions").
Comme précédement, nous ajoutons #include
<fftw.h> et créons un plan pour la transformée,
cette fois du type fftwnd_plan:
fftwnd_plan fftwnd_create_plan(int rank, const int *n,
fftw_direction dir, int flags);
rank est la dimension du tableau et peut contenir toute
valeur entière non-négative. L'argument suivant, n,
est un pointeur vers un tableau d'entiers d'une longueur rank
contenant les tailles (positives) de chaque dimension du tableau.
(Notez que le tableau sera stocké prioritairement dans l'ordre
des lignes. Voir la Section Format des
Tableaux Multi dimensions, pour des informations sur la priorité
donnée aux lignes.) Les deux dernier paramètres sont
les mêmes que pour fftw_create_plan. Nous avons
maintenant, néanmoins, un flag additionnel possible,
FFTW_IN_PLACE, depuis que fftwnd supporte
la transformée in-place vraie. Les flags multiples sont
combinés en utilisant un bit à bit ou (`|').
(Une transformée interne écrit
les données en sortie sur les données en entrée.
Elle demande donc moitié plus de mémoire que --et est
souvent plus rapide que-- sa transformée opposée
externe.)
Pour les transformées à deux ou trois dimensions,
FFTWND fournit des routines alternatives qui acceptent les tailles de
chaque dimension directement, plutôt d'indirectement par le
biais d'un rang et d'un tableau de tailles. Sinon, celui-ci est
identique à fftwnd_create_plan, et est quelque
fois plus adapté:
fftwnd_plan fftw2d_create_plan(int nx, int ny,
fftw_direction dir, int flags);
fftwnd_plan fftw3d_create_plan(int nx, int ny, int nz,
fftw_direction dir, int flags);
Une fois que le plan a été créé, vous
pouvez l'utiliser autant de fois que voulu pour les transformées
de même taille. Lorsque vous n'avez plus besoin du plan, vous
pouvez désallouer le plan en appelant
fftwnd_destroy_plan(plan).
Pour un plan donné, vous pouvez calculer la transformée d'un tableau de données en appelant:
void fftwnd_one(fftwnd_plan plan, fftw_complex *in, fftw_complex *out);
Ici, in et out pointent sur des tableaux
multi-dimension dans l'ordre des lignes, avec la taille spécifiée
lors de la création du plan. Dans le cas d'une transformée
interne, le paramètre out est ignoré et
les données en sortie sont stockées dans le tableau
in.Les résultats sont stockés dans
l'ordre, d'une manière non normalisée, avec la valeur
continue dans out[0]. Une transformée directe
suivie par une transformée inverse (ou vice-versa) rend la
donnée originale multipliée par la taille du tableau
(i.e. Le produit des dimensions). Voir Section Ce
Que Calcule Réellement FFTWND, pour une explication sur ce
que calcule FFTWND.
Par exemple, le code pour faire une FFT interne d'un tableau à trois dimensions peut ressembler à :
#include <fftw.h>
...
{
fftw_complex in[L][M][N];
fftwnd_plan p;
...
p = fftw3d_create_plan(L, M, N, FFTW_FORWARD,
FFTW_MEASURE | FFTW_IN_PLACE);
...
fftwnd_one(p, &in[0][0][0], NULL);
...
fftwnd_destroy_plan(p);
}
Notez que in est un tableau déclaré en
statique et est automatiquement ordonné par lignes mais nous
devons prendre l'adresse du premier élément de manière
à s'ajuster au type attendu par fftwnd_one. (Voir
Section Format des Tableaux
Multi-dimension.)
Si les données entrantes sont purement réelles, vous pouvez économiser d'à peu près un facteur de deux tant pour la durée que pour la mémoire en utilisant la transformée rfftw qui est une FFT spécialisée dans les données réelles. La sortie d'une telle transformée est un tableau halfcomplex, qui consiste en seulement la moitié des amplitudes DFT complexes (car les amplitudes dans les fréquences négatives pour les données réelles sont les conjugués complexes des amplitudes des fréquences positives).
En échange de ces avantages de vitesse et de mémoire, l'utilisateur sacrifie une partie de la simplicité de la transformée complexe de FFTW. Premièrement, pour permettre un maximum de performance, le format de sortie de la transformée réelle à une dimension est différent de celui utilisé par la transformée multi dimension. Deuxièmement, la transformée inverse (halfcomplex vers réelle) a un effet secondaire en détruisant son tableau d'entrée. Aucun de ces inconvénients ne doit poser de sérieux problèmes pour les utilisateurs mais il est important de les connaître. (Et l'inconvénient du format de sortie et les effets de bord de la transformée inverse peuvent être améliorés pour les transformées à une dimension au détriment de quelques performances, en utilisant, par exemple, à la place une transformée multi dimension avec un rang de un.)
Le calcul du plan est similaire à celui de la transformée
complexe. En premier, vous ajoutez #include <rfftw.h>.
Puis vous créez le plan (de type rfftw_plan) en
appelant:
rfftw_plan rfftw_create_plan(int n, fftw_direction dir, int flags);
n est la longueur des tableaux réels de
la transformée (même pour les transformées
halfcomplexe-vers-réel), et peut être tout entier
positif (bien que les tailles avec des petits facteurs soient
transformés plus efficacement). dir est soit
FFTW_REAL_TO_COMPLEX soit FFTW_COMPLEX_TO_REAL.
Le paramètre flags est le même que dans
fftw_create_plan.
Une fois créé, un plan peut être utilisé
pour tout nombre de transformée et est désalloué
si vous avez terminé par l'appel de rfftw_destroy_plan(plan).
Pour un plan donné, une tranformée réelle-vers-complexe ou complexe-vers-réelle est calculée en appelant :
void rfftw_one(rfftw_plan plan, fftw_real *in, fftw_real *out);
(Notez que fftw_real
est un alias du type virgule flottante pour lequel FFTW a été
compilé.) Selon la direction du plan, soit le tableau de
l'entrée soit de la sortie est halfcomplex, et est stocké
dans le format suivant :
r0, r1, r2, ..., rn/2, i(n+1)/2-1, ..., i2, i1
Ici, rk est la partie réelle de la kième
sortie et ik est la partie imaginaire. (Nous suivons ici
la convention du C pour laquelle la division d'entier est arondie à
l'inférieur, e.g. 7 / 2 = 3.) pour les tableaux halfcomplex
hc[], le kième composant a sa partie réelle
dans hc[k] et sa partie imaginaire dans hc[n-k],
avec l'exception de k == 0 ou
n/2 (le dernier seulement si n est pair ) --dans ces
deux cas, la partie imaginaire est à zéro dû à
la symétrie de la transformée réelle complexe et
n'est pas stocké. C'est pourquoi, la transformée de n
valeurs réelles est un tableau halfcomplex de longueur n,
et vice versa. (1)
C'est réellement seulement la moitié du spectre DFT de
la donnée. Bien que l'autre moitié puisse être
obtenue par la conjugaison complexe, elle n'est pas nécessaire
dans beaucoup d'applications comme les convolutions ou le filtrage.
Comme les transformées complexes, la transformée
RFFTW n'est pas normalisée et si elle est suivie directement
par une transformée inverse (ou vice-versa), on obtiendra la
donnée originale aggrandie à la taille de la longueur
du tableau, n.
Laissez nous réitérer notre avertissement: une
transformée FFTW_COMPLEX_TO_REAL a des effets de
bord en détruisant son entrée (halfcomplex). La
transformée FFTW_REAL_TO_COMPLEX, néanmoins,
laisse son entrée (réelle) inchangée comme vous
pouvez l'espérer. )
Comme exemple, nous avons,ici, le code sur la manière dont vous pouvez utiliser RFFTW pour calculer le spectre de puissance d'un tableau de réels (i.e. le carré de la valeur absolue des amplitudes DFT):
#include <rfftw.h>
...
{
fftw_real in[N], out[N], power_spectrum[N/2+1];
rfftw_plan p;
int k;
...
p = rfftw_create_plan(N, FFTW_REAL_TO_COMPLEX, FFTW_ESTIMATE);
...
rfftw_one(p, in, out);
power_spectrum[0] = out[0]*out[0]; /* DC component */
for (k = 1; k < (N+1)/2; ++k) /* (k < N/2 rounded up) */
power_spectrum[k] = out[k]*out[k] + out[N-k]*out[N-k];
if (N % 2 == 0) /* N is even */
power_spectrum[N/2] = out[N/2]*out[N/2]; /* Nyquist freq. */
...
rfftw_destroy_plan(p);
}
Les programmes utilisant RFFTW peuvent être linkés avec
-lrfftw -lfftw -lm sur Unix, ou avec les bibliothèques
FFTW, RFFTW, et mathématiques en général.
FFTW inclu une transformée multi-dimension pour les données réelles de tout rang. Comme pour les transformées réelles à une dimension, elle économise grosso-modo d'un facteur de deux le temps et le stockage par rapport aux transformées complexes de même taille. Donc comme pour ceux à une dimension ces gains se font au détriment d'une augmentation de complexité --le format de sortie est différent de la RFFTW à une dimension (et est plus similaire en ce sens à la FFTW complexe) et la transformée inverse (de complexe vers réel) a pour effet de bord d'écrire dans les données d'entrée.
Pour utiliser la transformée réelle multi-dimension,
vous devez d'abord ajouter #include <rfftw.h> et
créer alors un plan pour la taille et la direction de la
transformée qui vous intéresse :
rfftwnd_plan rfftwnd_create_plan(int rank, const int *n,
fftw_direction dir, int flags);
Le premier des deux paramètres décrit la taille des
données réelles (pas les données halfcomplexe,
qui auront des dimensions différentes). Les deux dernier
paramètres sont les mêmes que pour rfftw_create_plan.
De même que pour fftwnd, il y a deux versions alternatives de
cette routine, rfftw2d_create_plan et
rfftw3d_create_plan, qui sont quelque fois plus adaptées
pour les transformées à deux et trois dimensions. Aussi
comme dans fftwnd, rfftwnd supporte les transformées vraies
internes, spécifié par l'inclusion de FFTW_IN_PLACE
dans le flags.
Une fois créé, un plan peut être utilisé
quelque soit le nombre de transformées et est désalloué
en appelant rfftwnd_destroy_plan(plan).
Pour un plan donné, la transformée est calculée en appelant une de ces deux routines :
void rfftwnd_one_real_to_complex(rfftwnd_plan plan,
fftw_real *in, fftw_complex *out);
void rfftwnd_one_complex_to_real(rfftwnd_plan plan,
fftw_complex *in, fftw_real *out);
Comme il indiqué d'après leur type de nom ou paramètre,
la première fonction est pour une transformée
FFTW_REAL_TO_COMPLEX et la seconde pour une transformée
FFTW_COMPLEX_TO_REAL. (Nous aurions pu utiliser une
routine simple car la direction de la transformée est codée
dans le plan mais nous voulions correctement exprimer les types de
données des paramètres.) La dernière routine,
comme nous en avons déjà parlé, a l'effet de
bord d'écrire dans les données d'entrée (sauf
quand le rang du tableau est à un). Dans les deux cas, le
paramètre out est ignoré pour les
transformées interne.
Le format des tableaux complexes mérite une attention
particulière. Supposez que les données réelles
ont les dimensions n1 x n2 x ... x nd
(dans l'ordre des lignes). Alors après une transformée
réelle vers complexe, la sortie est un tableau n1 x
n2 x ... x (nd/2+1) de valeurs fftw_complex
ordonné en ligne, correspondant à un peu plus de la
moitié de la sortie de la transformée complexe
correspondante. (Notez que la division est arrondie en dessous).
Sinon, l'ordre des données est exactement le même que
dans le cas complexe. (En principe, la sortie peut être
exactement de la moitié de celle d'une transformée
complexe mais pour plus d'une dimension ceci requiert un format trop
compliqué pour être pratique.) Notez que contrairement
aux RFFTW multi dimensionnels, la part réelle et imaginaire
des amplitudes DFT sont ici stockées ensemble d'une manière
naturelle.
Comme la donnée complexe est légèrement plus
grande que la donnée réelle, quelques complications
peuvent survenir pour les transformées interne. Dans ce cas,
la dimension finale de cette donnée réelle doit être
augmentée avec des valeurs supplémentaires pour
s'adapter à la taille des données complexes --deux
extras si la dimension est paire et une seule si elle est impaire.
Ceci étant, la dernière dimension de la donnée
réelle doit contenir physiquement 2 * (nd/2+1)
fftw_real valeurs (exactement suffisant pour contenir
des données complexes). Cette taille de tableau physique,
néanmoins, change la taille logique du tableau --seules
nd valeurs sont réellement stockées dans la
dernière dimension et nd est dans la dernière
dimension passée à rfftwnd_create_plan.
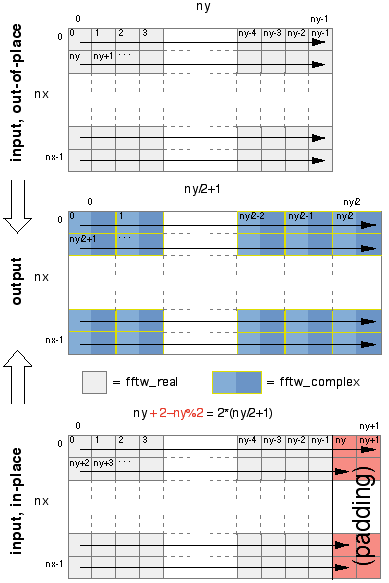
Par exemple, considérons la transformée d'un tableau
à deux dimensions de nx par ny. La
sortie de la transformée rfftwnd est un tableau
réel à deux dimensions de la taille de nx
par ny/2+1, où la dimension y a été
diminuée de moitié à cause de la redondance de
sa sortie. fftw_complex ayant deux fois la taille de
fftw_real, le tableau de sortie est légèrement
plus grand que celui d'entrée. Donc si nous voulons calculer
la transformée in place, nous devons étendre le
tableau d'entrée pour qu'il soit de la taille nx
par 2*(ny/2+1). Si ny est pair, alors on
ajoute deux éléments à la fin de chaque ligne
(qui n'ont pas besoin d'être initialisés car ils ne sont
utilisés que pour la sortie). L'illustration suivante décrit
les tableaux d'entrée et de sortie que nous venons de décrire
à la fois pour les transformées externes et internes
(les flèches indiquent les emplacements mémoires
consécutifs):
La figure 1 décrit les tableaux d'entrée et de sortie que nous venons de décrire pour les transformées externes et internes (les flèches indiquent les emplacements mémoires consécutifs).
Les transformées RFFTWND ne sont pas normalisées donc une transformée directe suivie par une inverse redonnera la donnée originale multipliée par le nombre des éléments de données réelles --ce qui signifie, le produit des dimensions (logique) de la donnée réelle.
Dessous, nous illustrons l'utilisation de RFFTWND en montrant
comment vous pouvez l'utiliser pour calculer la convolution
(cyclique) des tableaux réels à deux dimensions a
et b (utilisant le fait qu'une convolution correspond à
un produit point à point de la transformée de Fourier).
Pour la diversité, la transformée interne est utilisée
pour la FFT directe et la transformée externe est utilisée
pour la transformée inverse.
#include <rfftw.h>
...
{
fftw_real a[M][2*(N/2+1)], b[M][2*(N/2+1)], c[M][N];
fftw_complex *A, *B, C[M][N/2+1];
rfftwnd_plan p, pinv;
fftw_real scale = 1.0 / (M * N);
int i, j;
...
p = rfftw2d_create_plan(M, N, FFTW_REAL_TO_COMPLEX,
FFTW_ESTIMATE | FFTW_IN_PLACE);
pinv = rfftw2d_create_plan(M, N, FFTW_COMPLEX_TO_REAL,
FFTW_ESTIMATE);
/* aliases for accessing complex transform outputs: */
A = (fftw_complex*) &a[0][0];
B = (fftw_complex*) &b[0][0];
...
for (i = 0; i < M; ++i)
for (j = 0; j < N; ++j) {
a[i][j] = ... ;
b[i][j] = ... ;
}
...
rfftwnd_one_real_to_complex(p, &a[0][0], NULL);
rfftwnd_one_real_to_complex(p, &b[0][0], NULL);
for (i = 0; i < M; ++i)
for (j = 0; j < N/2+1; ++j) {
int ij = i*(N/2+1) + j;
C[i][j].re = (A[ij].re * B[ij].re
- A[ij].im * B[ij].im) * scale;
C[i][j].im = (A[ij].re * B[ij].im
+ A[ij].im * B[ij].re) * scale;
}
/* inverse transform to get c, the convolution of a and b;
this has the side effect of overwriting C */
rfftwnd_one_complex_to_real(pinv, &C[0][0], &c[0][0]);
...
rfftwnd_destroy_plan(p);
rfftwnd_destroy_plan(pinv);
}
Nous accédons aux sorties complexes de la transformée
interne en charger chaque tableau réel avec un pointeur
fftw_complex. Etant un pointeur "plat", nous
devons calculer l'index de ligne ij explicitement dans
la boucle de production de la convolution. De manière à
normaliser la convolution, nous devons multiplier par un facteur
d'échelle --nous pouvons le faire soit avant, soit après
la transformée inverse et choisir le précédent
car cela évite la nécessité d'une boucle
supplémentaire. Notez les limites de boucles et les dimensions
des différents tableaux.
Comme pour les RFFTW à une dimension, les transformées
FFTW_COMPLEX_TO_REAL externe ont l'effet de bord
d'écrire dans les données d'entrée. (La
transformée réel-vers-complexe, d'un autre coté,
garde les données du tableau d'entrée intactes.) Si
vous utilisez une transformée RFFTWND de rang un, néanmoins,
cet effet de bord n'apparait pas. A cause de ce fait, (et le format
de sortie le plus simple), les utilisateurs peuvent trouver
l'interface RFFTWND plus adaptée que la RFFTW pour les
transformées à une dimension. Néanmoins, RFFTWND
à une dimension est légèrement plus lente que
RFFTW car RFFTWND utilise un buffer tableau supplémentaire en
interne.
Cette section décrit le format dans lequel les tableaux
multi dimensionnels sont stockés. Nous avons senti qu'une
discussion détaillée sur ce sujet était
nécessaire car le sujet est souvent une source de confusion et
il existe une série de plusieurs formats. Bien que les
commentaires ci-dessous se réfèrent à fftwnd,
ils sont aussi applicables aux routines rfftwnd.
Les tableaux multi dimension passés à fftwnd
sont supposés être stockés en un simple bloc
continu dans l'ordre des lignes
(quelque fois appelé "ordre C"). Basiquement,
cela signifie que lorsque vous vous déplacez vers une zone de
mémoire adjacente, le premier des index de dimension varie
plus lentement et le dernier index de dimension varie plus
rapidement.
Pour être plus explicite, laissez nous considérer un tableau de rang d dont les dimensions sont n1 x n2 x n3 x ... x nd. Maintenant nous spécifions une zone dans la mémoire par la séquence d'indices (basés sur zéro), un pour chaque dimension : (i1, i2, i3,..., id). Si le tableau est stocké dans l'ordre des lignes alors cet élément est stocké à la position id + nd * (id-1 + nd-1 * (... + n2 * i1)).
Notez que chaque élément du
tableau doit être du type fftw_complex; i.e. une
paire (réelle, imaginaire) de nombres (double-précision).
Notez aussi que, dans fftwnd, l'expression au-dessus est
multipliée par le décalage pour avoir l'index du
tableau réel --ceci est utile dans les situations où
chaque élément du tableau multi dimension est
réellement une structure de donnée ou tout autre
tableau et vous voulez simplement transformer un champ simple. Dans
la plupart des cas, néanmoins, vous utilisez un décalage
de 1.
Les lecteurs venant du monde fortran sont habitués aux tableaux stockés dans l'ordre des colonnes (quelque fois "ordre Fortran"). C'est essentiellement l'opposé exact de l'ordre par ligne dans le sens qu'ici, le premier index de dimension varie le plus rapidement.
Si vous avez un tableau stocké dans un ordre par colonne et
que vous voulez le transformer en utilisant fftwnd,
c'est assez facile à faire. Lors de la création du
plan, passez simplement les dimensions du tableau à
fftwnd_create_plan dans l'ordre inverse. Par
exemple, si votre tableau est une matrice de rang trois N x M x
L dans l'ordre par colonne, vous devez passer les dimensions
du tableau comme si c'était une matrice L x M x N
(ce qu'elle est de la perspective de fftwnd). C'est déjà
réalisé par les routines associées à FFTW
Fortran (voir Section Appeler FFTW à
partir de Fortran).
Les tableaux multi dimension déclarés statiquement
(qui ne sont, à la compilation, pas nécessairement
faits avec le mot clé static) en C sont déjà
dans l'ordre des lignes. Vous n'avez rien de spécial à
faire pour les transformer. (Voir Section Formation
sur la Transformée Complexe Multi dimension, pour un
exemple de ce type de code).
Souvent, spécialement pour les grands tableaux, il est souhaitable d'allouer les tableaux dynamiquement lors du calcul. Ce n'est pas trop difficile à réaliser bien que cela ne soit aussi direct pour les tableaux multidimensionnel que pour les simples.
Créer le tableau est simple : utiliser
une routine d'allocation dynamique telle malloc, allouer
un tableau suffisamment grand pour stocker N valeurs fftw_complex,
où N est le produit des tailles des dimensions du tableau
(i.e. Le nombre total valeurs complexes dans le tableau). Par
exemple, ici vous trouvez le code pour allouer un tableau de rang 3
de 5x12x27 :
fftw_complex *an_array; an_array = (fftw_complex *) malloc(5 * 12 * 27 * sizeof(fftw_complex));
Accéder aux éléments du tableau est, néanmoins,
plus délicat -vous ne ne pouvez pas simplement utiliser les
multiples applications de l'opérateur `[]' comme
vous le pourriez pour les tableaux statiques. Au lieu de cela, vous
devez explicitement calculer l'offset dans le tableau en utilisant
les formules données plus tôt dans les tableaux dans
l'ordre des lignes. Par exemple, pour accéder (i,j,k)-ième
élément du tableau alloué ci-dessus, vous devez
utiliser l'expression an_array[k + 27 * (j + 12 * i)].
Cette difficulté peut néanmoins être allégée en définissant les macros appropriées ou en créant en C++ une classe pour remplacer l'opérateur `()'.
Une méthode différente pour allouer les tableaux
multi dimension en C est souvent suggérée mais elle est
incompatible avec fftwnd : l'utiliser donnera à
FFTW une mort douleureuse. Nous discutons néanmoins
de la technique ici car elle est bien connue et utilisée.
Cette méthode crée des tableaux de pointeurs de... etc.
Par exemple, la méthode analogue ressemble à :
int i,j;
fftw_complex ***a_bad_array; /* another way to make a 5x12x27 array */
a_bad_array = (fftw_complex ***) malloc(5 * sizeof(fftw_complex **));
for (i = 0; i < 5; ++i) {
a_bad_array[i] =
(fftw_complex **) malloc(12 * sizeof(fftw_complex *));
for (j = 0; j < 12; ++j)
a_bad_array[i][j] =
(fftw_complex *) malloc(27 * sizeof(fftw_complex));
}
Comme vous pouvez le voir, ce tri de tableaux est inadapté
pour l'allocation (et la désallocation). D'un autre coté,
ce système possède l'avantage d'avoir le (i,j,k)-ième
élément référencé simplement par
a_bad_array[i][j][k].
Si vous aimez cette technique et que vous voulez améliorer
l'efficacité de l'accès au tableau mais que voulez
toujours le passer dans FFTW, vous pouvez utiliser une méthode
hybride. Allouez le tableau en un seul bloc continu et déclarez
aussi un tableau de tableau de pointeurs qui pointent vers les zones
adaptées du bloc. Ce type de trucs est au-delà du champ
de cette documentation : pour plus d'informations sur les les
tableaux multi dimension en C, voyez la FAQ
comp.lang.c.
FFTW implémente une
méthode pour sauvegarder et retrouver les plans sur disque. En
fait, ce qui est réalisé est un plus global que sauver
et charger les plans. Le mécanisme est appelé wisdom.
Ici, nous survolons ce système. Voyez la Section Référence
FFTW, pour une discussion moins superficielle (mais plus
complète) sur comment utiliser wisdom dans FFTW.
Les plans créés avec l'option FFTW_MEASURE
produisent une FFT presque optimale mais cela peut prendre du temps
car FFTW doit réellement mesurer le temps de plusieurs plans
et sélectionner le meilleur. Cela a été conçu
pour les situations où plusieurs transformées de la
même taille doivent être calculées et le temps de
démarrage est hors de propos. Pour un court temps
d'initialisation mais une transformée légèrement
plus lente, nous avons fourni FFTW_ESTIMATE. Le
mécanisme wisdom est une manière d'obtenir
le meilleur des deux mondes. Il existe, néanmoins quelques
avertissements dont l'utilisateur doit être conscient dans
l'utilisation de wisdom. Pour cette raison, wisdom
est un système optionnel qui n'est pas validé par
défaut.
Au plus simple, wisdom fournit
une manière de sauvegarder les plans sur le disque pour qu'ils
puissent être réutilisés lors de l'execution des
autres programmes. Vous pouvez créer un plan avec les flags
FFTW_MEASURE,FFTW_USE_WISDOM, et sauver alors wisdom
en utilisant fftw_export_wisdom :
plan = fftw_create_plan(..., ... | FFTW_MEASURE | FFTW_USE_WISDOM);
fftw_export_wisdom(...);
La prochaine fois que vous lancez le programme, vous pouvez retrouver
wisdom avec fftw_import_wisdom, et recréer
alors le plan en utilisant le plan avec les mêmes drapeaux que
précédement. Cette fois, néanmoins, le même
plan optimal sera créé très rapidement sans
mesure. (FFTW aura encore besoin de temps,néanmoins, pour
calculer les tables trigonométriques). La sortie de base est :
fftw_import_wisdom(...);
plan = fftw_create_plan(..., ... | FFTW_USE_WISDOM);
Wisdom est, néanmoins, plus qu'une simple
machine de mémorisation. FFTW wisdom inclue tout
le savoir et les mesures qui étaient utilisées pour
créer un plan d'une taille donnée. C'est pourquoi, les
wisdom existants sont aussi appliqués à la
création ds autres plans de différentes tailles.
A chaque fois qu'un plan est créé avec les drapeaux
FFTW_MEASURE et FFTW_USE_WISDOM, wisdom
est généré. C'est pourquoi les plans pour toute
transformée à la factorisation identique seront
calculés plus rapidement pourvu qu'ils utilisent le drapeau
FFTW_USE_WISDOM. En fait, pour les transformées
avec les mêmes facteurs et une taille égale ou plus
petite, aucune mesure n'est nécessaire et un plan est créé
en un temps négligeable!
Par exemple, supposez que vous créez un plan pour N = 216.
Alors, pour toute puisance de deux égale ou inférieure,
FFTW peut créer un plan (avec les mêmes directions et
drapeaux) rapidement en utilisant la wisdom précalculée.
Même pour les grande puisances de deux ou les tailles qui ont
une puissance de deux fois tout autre facteur premier, les plans
seront calculés plus rapidement qu'ils ne le seraient
autrement (bien que des mesures doivent encore être réalisées).
wisdom est cumulatif et est stocké dans une
structure de donnée globale et privée gérée
en interne par FFTW. Cet espace de stockage est minimal,
proportionnel au logarithme des tailles pour lequel wisdom
a été généré. wisdom
peut être oublié (et sa mémoire associée
libérée) par un appel à fftw_forget_wisdom();
sinon il est rappelé jusqu'à ce que le programme se
termine. Il peut être exporté vers un fichier, une
chaine ou tout autre moyen en utilisant fftw_export_wisdom
et être retrouvé pendant une execution ultérieure
du programme (ou un différent programme) en utilisant
fftw_import_wisdom (ces fonction sont décrites
ci-dessous).
wisdom est incorporé à FFTW à un
niveau très bas et le même wisdom peut être
utilisé pour les transformées une ou multi dimension et
même être une extension parallèle à FFTW.
Incluez simplement FFTW_USE_WISDOM comme drapeau pour
tous les plans créés (i.e., toujours plannifier
sagement).
Les plans créés avec FFTW_ESTIMATE
peuvent utiliser wisdom, mais ne peuvent pas le générer;
seuls les plans FFTW_MEASURE produisent réellement
wisdom. Aussi, les plans ne peuvent utiliser wisdom
que s'ils sont crées avec la même direction et les même
drapeaux. Par exemple, une taille de transformée 42
FFTW_BACKWARD n'utilisera pas un wisdom
produit par une transformée de 42 FFTW_FORWARD.
La seule exeption à cette règle est que les plans
FFTW_ESTIMATE peuvent utiliser wisdom à
partir des plans FFTW_MEASURE.
For in much wisdom is much grief, and he that increaseth knowledge increaseth sorrow. [Ecclesiastes 1:18]
Il existe des pièges dans l'utilisation de wisdom,
dans le sens où il peut nier l'aptitude de FFTW à
s'adapter au changement de matériel et d'autres conditions.
Par exemple, il serait parfaitement possible d'exporter wisdom
d'un programme tournant sur un processeur et l'importer dans un
programme sur un autre processeur. En faisant ceci, néanmoins,
on utilisera pour le second programme, un plan optimisé pour
le premier processeur, à la place de celui optimisé
spécifiquement.
Il devrait être sans danger de réutiliser wisdom
tant que le matériel et les binaires du programme restent
inchangés. (Le plan optimal peut réellement changer
même entre les exécutions des même binaires sur
des machines identiques, dûes à des différences
dans les environnements de mémoire virtuelles, etc... Les
utilisateurs sérieusement intéressés dans les
performances devraient aussi s'inquiéter de ces problèmes).
Il est possible que si le même wisdom est utilisé
pour deux programmes binaires différents, même tournant
sur la même machine, le plan puisse être sous-optimal à
cause de la différence d'alignements de code. Il est donc
sensé de recréer wisdom à chaque
fois qu'une application est recompilée. Plus le matériel
et le logiciel sous-jacent changent entre les créations de
wisdom et son utilisation, plus augmente le risque de
plans sous-optimaux.
void fftw_export_wisdom_to_file(FILE *output_file); fftw_status fftw_import_wisdom_from_file(FILE *input_file);
fftw_export_wisdom_to_file
écrit wisdom vers output_file, qui
doit être un fichier ouvert pour l'écriture.
fftw_import_wisdom_from_file lit wisdom
depuis input_file, qui doit être un fichier ouvert
pour la lecture et retourne FFTW_SUCCESS s'il y a un
succès et FFTW_FAILURE dans l'autre cas. Dans les
deux cas, le fichier est gardé ouvert et doit être fermé
par l'appelant. Il est parfaitement fin si d'autres données
restent avant ou après wisdom dans le fichier,
aussi longtemps que le fichier est positionné au début
des données de wisdom avant l'importation.
char *fftw_export_wisdom_to_string(void); fftw_status fftw_import_wisdom_from_string(const char *input_string)
fftw_export_wisdom_to_string
alloue une chaine, exporte wisdom dans son format
terminé par un NULL et retourne un pointeur à
la chaine. S'il y a une erreur dans l'allocation ou l'écriture
d'une donnée il retourne un NULL. L'appelant est
responsable de la désallocation de la chaine (avec fftw_free)
lorsque l'on travaille avec. fftw_import_wisdom_from_string
importe wisdom à partir de input_string,
returne FFTW_SUCCESS si c'est un succès et
FFTW_FAILURE sinon.
Exporter wisdom
n'affecte pas le stockage de wisdom. Importer wisdom
le met en supplément dans le stock actuel plutot que que le
remplacer (excepté lorsqu'il y a un conflit avec wisdom,
auquel cas l'ancien wisdom est écarté). Le
format de wisdom exporté est un LISP
"nerd-lisible" comme un texte ASCII; nous ne le
documenterons pas ici excepté pour noter qu'il est insensible
aux espaces blancs (les utilisateurs intéressés peuvent
nous contacter pour plus de détails).
Voir la Section Référence
FFTW pour plus d'informations et pour une description sur la
manière dont vous pouvez implémenter l'import/export de
wisdom pour les autres médias en plus des les
fichiers et les chaines.
Ce qui suit est un bref exemple dans lequel wisdom
est lu à partir d'un fichier, un plan est créé
(pouvant générer en plus wisdom), et alors
wisdom est exporté vers une chaine et imprimé
sur stdout.
{
fftw_plan plan;
char *wisdom_string;
FILE *input_file;
/* open file to read wisdom from */
input_file = fopen("sample.wisdom", "r");
if (FFTW_FAILURE == fftw_import_wisdom_from_file(input_file))
printf("Error reading wisdom!\n");
fclose(input_file); /* be sure to close the file! */
/* create a plan for N=64, possibly creating and/or using wisdom */
plan = fftw_create_plan(64,FFTW_FORWARD,
FFTW_MEASURE | FFTW_USE_WISDOM);
/* ... do some computations with the plan ... */
/* always destroy plans when you are done */
fftw_destroy_plan(plan);
/* write the wisdom to a string */
wisdom_string = fftw_export_wisdom_to_string();
if (wisdom_string != NULL) {
printf("Accumulated wisdom: %s\n",wisdom_string);
/* Just for fun, destroy and restore the wisdom */
fftw_forget_wisdom(); /* all gone! */
fftw_import_wisdom_from_string(wisdom_string);
/* wisdom is back! */
fftw_free(wisdom_string); /* deallocate it since we're done */
}
}
Go to the first, previous, next, last section, table of contents.